Learning Rate Scheduling#
Part of the traditional machine learning recipe is to decay our learning rate (LR) over time. This ensures that we get fast learning early on, but can get that last push of performance near the edge. Let’s see how much this matters, and if we can get away without it.
Classical Optimization: Decay your learning rate#
In classical optimization theory, learning rate must decay for us to get certain convergence guarantees. The intution is that if we stay at a constant learning rate forever, we’ll end up bouncing around the optimum and won’t converge to the exact point. By decaying the change to zero, we will eventually converge to a fixed point at minimum loss.
Of course, it’s one thing for a technique to be theoretically sound, and other for it to work in practice…
Experiment: Learning rate decay with CIFAR-10#
Let’s try out some differnt learning rate schedules on neural networks. We’ll use the CIFAR-10 dataset this time, which is a set of 50,000 colored images and 10 classes. We’ll use a small vision transformer as our network, and the Adam optimizer as a base.
from keras.datasets import cifar10
(train_images, train_labels), (valid_images, valid_labels) = cifar10.load_data()
id_to_text = ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
print('Dataset size:', train_images.shape)
fig, axs = plt.subplots(1, 10, figsize=(20, 5))
for i, ax in enumerate(axs):
ax.imshow(train_images[i], cmap='gray')
ax.title.set_text(f'{id_to_text[train_labels[i][0]]}')
ax.axis('off')
Dataset size: (50000, 32, 32, 3)

Show code cell content
from einops import rearrange
def get_1d_sincos_pos_embed_from_grid(embed_dim, pos):
assert embed_dim % 2 == 0
omega = jnp.arange(embed_dim // 2, dtype=jnp.float32) / (embed_dim // 2)
omega = 1. / 10000**omega # (D/2,)
pos = pos.reshape(-1) # (M,)
out = jnp.einsum('m,d->md', pos, omega) # (M, D/2), outer product
emb = jnp.concatenate([jnp.sin(out), jnp.cos(out)], axis=1) # (M, D)
return emb
def get_2d_sincos_pos_embed(embed_dim, length):
grid_size = int(length ** 0.5)
assert grid_size * grid_size == length
grid_hw = jnp.arange(grid_size, dtype=jnp.float32)
grid = jnp.stack(jnp.meshgrid(grid_hw, grid_hw), axis=0)
grid = grid.reshape([2, 1, grid_size, grid_size])
emb_h = get_1d_sincos_pos_embed_from_grid(embed_dim // 2, grid[0]) # (H*W, D/2)
emb_w = get_1d_sincos_pos_embed_from_grid(embed_dim // 2, grid[1]) # (H*W, D/2)
pos_embed = jnp.concatenate([emb_h, emb_w], axis=1) # (H*W, D)
return jnp.expand_dims(pos_embed, 0) # (1, H*W, D
class TinyViT(nn.Module):
features: int = 128
patch_size: int = 8
num_classes: int = 10
dropout: float = 0.3
@nn.compact
def __call__(self, x, deterministic=False):
patch_tuple = (self.patch_size, self.patch_size)
num_patches = (x.shape[1] // self.patch_size)
x = nn.Conv(self.features, patch_tuple, patch_tuple, use_bias=True, padding="VALID")(x) # Patch Embed
x = rearrange(x, 'b h w c -> b (h w) c', h=num_patches, w=num_patches)
x = x + get_2d_sincos_pos_embed(self.features, num_patches**2)
x = jnp.concatenate([x, nn.Embed(1, self.features)(jnp.zeros((x.shape[0], 1), dtype=jnp.int32))], axis=1) # Class Token
for _ in range(4):
y = nn.LayerNorm()(x)
y = nn.MultiHeadDotProductAttention(num_heads=4, dropout_rate=self.dropout, deterministic=deterministic)(y, y)
x = x + y
y = nn.LayerNorm()(x)
y = nn.Dense(self.features * 2)(y)
y = nn.gelu(y)
y = nn.Dropout(rate=self.dropout, deterministic=deterministic)(y)
y = nn.Dense(self.features)(y)
y = nn.Dropout(rate=self.dropout, deterministic=deterministic)(y)
x = x + y
x = x[:, 0]
x = nn.Dense(self.num_classes)(x)
return x
def sample_batch(key, batchsize, images, labels):
idx = jax.random.randint(key, (batchsize,), 0, images.shape[0])
return images[idx], labels[idx]
def zero_params(params):
return jax.tree_map(lambda x: jnp.zeros_like(x), params)
def train_cifar(optimizer_fn, init_opt_fn, max_steps):
train_losses = []
classifier = TinyViT()
key = jax.random.PRNGKey(0)
key, param_key = jax.random.split(key)
v_images, v_labels = sample_batch(param_key, 256, valid_images, valid_labels)
params = classifier.init({'params': param_key, 'dropout': param_key}, v_images)['params']
opt_state = init_opt_fn(params)
@jax.jit
def update_fn(key, params, opt_state, images, labels, step, max_steps):
def loss_fn(p, x, y):
x = x / 255.0
onehot_labels = jax.nn.one_hot(y[:, 0], 10)
logits = classifier.apply({'params': p}, x, rngs={'dropout': key}, deterministic=False)
loss = jnp.mean(jnp.sum(-nn.log_softmax(logits) * onehot_labels, axis=-1))
return loss
grad_fn = functools.partial(jax.value_and_grad(loss_fn), x=images, y=labels)
loss, params, opt_state = optimizer_fn(params, opt_state, grad_fn, step, max_steps)
return loss, params, opt_state
for i in tqdm.tqdm(range(max_steps)):
key, data_key, update_key = jax.random.split(key, 3)
images, labels = sample_batch(data_key, 128, train_images, train_labels)
loss, params, opt_state = update_fn(update_key, params, opt_state, images, labels, i, max_steps)
train_losses.append(np.array(loss))
return np.array(train_losses)
def plot_losses(losses, labels, title, colors=None, ylim=2):
fig, axs = plt.subplots(1, figsize=(5, 3))
for i, (label, loss) in enumerate(zip(labels, losses)):
loss = np.convolve(loss, np.ones(1000), 'valid') / 1000
axs.plot(loss, label=label, color=colors[i] if colors else None)
axs.legend()
axs.set_ylim(-0.05, ylim)
axs.set_title(title)
plt.show()
def adam_optimizer_custom(lr_schedule, params, opt_state, grad_fn, step, max_steps):
loss, grads = grad_fn(params)
momentum, variance = opt_state
b1, b2 = 0.9, 0.999
new_momentum = jax.tree_map(lambda m, g: b1 * m + (1-b1) * g, momentum, grads)
new_variance = jax.tree_map(lambda v, g: b2 * v + (1-b2) * g ** 2, variance, grads)
m_hat = jax.tree_map(lambda m: m / (1 - b1 ** (step + 1)), new_momentum)
v_hat = jax.tree_map(lambda v: v / (1 - b2 ** (step + 1)), new_variance)
update = jax.tree_map(lambda m, v: m / (jnp.sqrt(v) + 1e-6), m_hat, v_hat)
lr = lr_schedule(step, max_steps)
new_params = jax.tree_map(lambda p, u: p - lr * u, params, update)
return loss, new_params, (new_momentum, new_variance)
init_opt_fn = lambda p : (zero_params(p), zero_params(p))
adam_constant = functools.partial(adam_optimizer_custom, lambda x, y: 0.001)
constant_loss = train_cifar(adam_constant, init_opt_fn, 100_000)
linear_losses = []
for max_steps in [100_000, 75_000, 50_000, 25000]:
adam_linear = functools.partial(adam_optimizer_custom, lambda step, max_steps: 0.001 * (1 - (step / max_steps)))
linear_losses.append(train_cifar(adam_linear, init_opt_fn, max_steps))
plot_losses([constant_loss] + linear_losses,
['Constant LR'] + [f'Linear Decay {d}' for d in [100_000, 75_000, 50_000, 25000]], 'Train Loss', ylim=1)
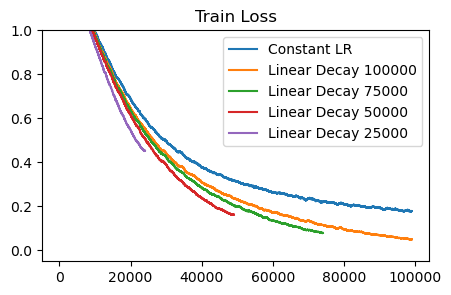
Learning rate decay consistently helps. As as baseline, the blue ‘Constant LR’ curve shows us what happens when we just use a fixed learning rate. The network is still improving, and there’s definitely progress being made at every step. However, we get a consistent gain from using linear decay, where we simply scale the LR down linearly until it reaches zero at the end of training. The base learning rate (0.001) was found by doing a sweep. So, it is not a problem of having too high of a learning rate throughout training.
Does the type of decay matter? Let’s try out cosine decay, which decays LR following the first cycle of a cosine. We’ll also try out a simple stepwise decay, which uses a constant learning rate for most of training, then drops to a lower rate near the end.
adam_cosine = functools.partial(adam_optimizer_custom, lambda step, max_steps: 0.001 * (
0.5 * (1 + jnp.cos(jnp.pi * (step / max_steps)))))
adam_stepwise = functools.partial(adam_optimizer_custom, lambda step, max_steps: 0.001 * (
jnp.where(step/max_steps > 0.25, 0.1, 1)))
adam_stepwise2 = functools.partial(adam_optimizer_custom, lambda step, max_steps: 0.001 * (
jnp.where(step/max_steps > 0.75, 0.1, 1)))
cosine_loss = train_cifar(adam_cosine, init_opt_fn, 100_000)
stepwise_loss = train_cifar(adam_stepwise, init_opt_fn, 100_000)
stepwise2_loss = train_cifar(adam_stepwise2, init_opt_fn, 100_000)
100%|██████████| 100000/100000 [04:11<00:00, 397.67it/s]
plot_losses([constant_loss, linear_losses[0], cosine_loss, stepwise_loss, stepwise2_loss],
['Constant LR', 'Linear Decay', 'Cosine Decay', 'Stepwise at 25%', 'Stepwise at 75%'], 'Train Loss', ylim=1)
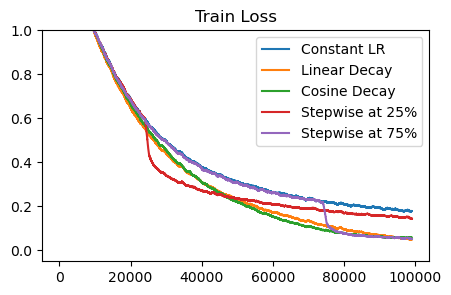
Most decay strategies converge to the same lower loss point. So, it seems that the decay schedule itself doesn’t matter, but rather the fact that decay happens at all is important. Let’s refer to the parameters achieving the lower loss as the smoothed parameters. Training with a high LR is good for making progress, but it doesn’t fully smooth the parameters – we need to decay.
The stepwise decay shows the most interesting finding. Even with a constant LR, we’re still making learning progress – it’s just that we haven’t fully realized the gains yet. By lowering the learning rate near the end, we can smooth out the parameters and get low loss. Notably, it’s still faster to train with the large LR for most of training. If we switch to a lower LR at 25% of the way, we get a gain from smoothing, but learning becomes slower from then on.
An alterative: Parameter Averaging#
A natural question asks, is there a way to have smoothed parameters throughout the entire training run? A key intution is a relationship between LR decay and parameter averaging. Intuitively, when training with a high LR, some parameters may oscillate. A slower LR lets these parameters properly converge to their smoothed values. Another way we can achieve this is through parameter averaging – i.e, we use an average of past parameters rather than the current ones. This lets oscillations cancel out.
Linear LR decay is in fact quite similar to uniform averaging with a constant LR. Imagine applying a gradient halfway through training. With linear LR decay, we apply the gradient at half magnitude. With uniform averaging, that gradient is present in the last half of the parameter sequence, giving it a half-weighting in the final average. The difference of course is where the gradient is calculate – with linear LR decay, we calculate on the smoothed parameters, wheras with parameter averaging, we calculate on the live parameters.
Let’s plot some runs where we use parameter averaging. We will try two standard strategies – Polyak (uniform) averaging, which assigns equal weight to all past parameters, and exponential moving averaging, which values recent parameters more. For our exponential strategy, we will use the same bias-correction strategy as Adam.
def adam_optimizer_averaging(lr_schedule, params, opt_state, grad_fn, step, max_steps, avg_type='polyak'):
loss, grads = grad_fn(params)
momentum, variance, smooth_params = opt_state
b1, b2 = 0.9, 0.999
new_momentum = jax.tree_map(lambda m, g: b1 * m + (1-b1) * g, momentum, grads)
new_variance = jax.tree_map(lambda v, g: b2 * v + (1-b2) * g ** 2, variance, grads)
m_hat = jax.tree_map(lambda m: m / (1 - b1 ** (step + 1)), new_momentum)
v_hat = jax.tree_map(lambda v: v / (1 - b2 ** (step + 1)), new_variance)
update = jax.tree_map(lambda m, v: m / (jnp.sqrt(v) + 1e-6), m_hat, v_hat)
lr = lr_schedule(step, max_steps)
new_params = jax.tree_map(lambda p, u: p - lr * u, params, update)
if avg_type == 'polyak':
c = 1 / (step + 1)
new_smooth_params = jax.tree_map(lambda x, y: x * (1-c) + y * c, smooth_params, new_params)
smooth_params_hat = new_smooth_params
elif 'exponential' in avg_type:
ema_rate = 0.9999 if avg_type == 'exponential-0.9999' else 0.999
new_smooth_params = jax.tree_map(lambda x, y: x * ema_rate + y * (1-ema_rate), smooth_params, new_params)
smooth_params_hat = jax.tree_map(lambda x: x / (1 - ema_rate ** (step + 1)), new_smooth_params)
loss, _ = grad_fn(smooth_params_hat) # Eval with smoothed params
return loss, new_params, (new_momentum, new_variance, new_smooth_params)
init_opt_fn_polyak = lambda p : (zero_params(p), zero_params(p), p)
init_opt_fn = lambda p : (zero_params(p), zero_params(p), zero_params(p))
# adam_polyak = functools.partial(adam_optimizer_averaging, lambda x, y: 0.001, avg_type='polyak')
# polyak_loss = train_cifar(adam_polyak, init_opt_fn_polyak, 100_000)
adam_exponential = functools.partial(adam_optimizer_averaging, lambda x, y: 0.001, avg_type='exponential-0.9999')
exponential_loss = train_cifar(adam_exponential, init_opt_fn, 100_000)
adam_exponential = functools.partial(adam_optimizer_averaging, lambda x, y: 0.001, avg_type='exponential-0.999')
exponential2_loss = train_cifar(adam_exponential, init_opt_fn, 100_000)
100%|██████████| 100000/100000 [05:13<00:00, 319.20it/s]
100%|██████████| 100000/100000 [05:13<00:00, 318.83it/s]
plot_losses([constant_loss, cosine_loss, polyak_loss, exponential_loss, exponential2_loss],
['Constant LR', 'Cosine Decay', 'Polyak Avg', 'Exp Avg (0.9999)', 'Exp Avg (0.999)'], 'Train Loss', ylim=1.5)
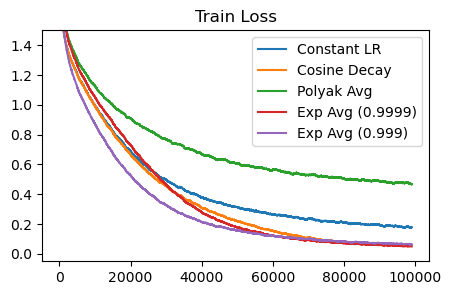
At the end of training, exponential averaging matches the performance of cosine decay. Remember that cosine decay is scheduled, whereas exponential averaging can be run indefinitely. Polyak averaging isn’t as good – it actually lags behind the non-averaging baseline. Perhaps this is because of bias that is introduced from weighting earlier parameters equally? At the limit, polyak averaging will converge to the proper smoothed parameters, but it may take a long time in practice.
Schedule-Free Optimization#
Taking our connection between LR decay and parameter averaging, we can understand the insights behind schedule-free optimization (Defazio 2024). The core of their proposed method is to keep track of smoothed parameters using parameter averaging. When calculating the gradient, we calculate using a linear combination of the live and smoothed parameters.
combo_params = (1-b) * live_params + b * smooth_params
live_params = live_params + grad(combo_params)
smooth_params = (1-c) * smooth_params + c * live_params (Polyak averaging)
The intution is to generalize the two approaches we had before (LR decay and parameter averaging). Instead of evaluating the gradient at either the smoothed or live parameters, we use a middle ground between them. b is usually a high value (0.9), so we’re mostly using the smoothed parameters.
def adam_optimizer_schedulefree(lr_schedule, params, opt_state, grad_fn, step, max_steps, avg_type='polyak'):
variance, smooth_params = opt_state
b1, b2 = 0.9, 0.999
ema_rate = 0.9999
if avg_type == 'polyak':
smooth_params_hat = smooth_params
elif avg_type == 'exponential':
smooth_params_hat = jax.tree_map(lambda x: x / (1 - ema_rate ** (step + 1)), smooth_params)
combo_params = jax.tree_map(lambda p, sp: (1-b1)*p + b1*sp, params, smooth_params_hat)
loss, grads = grad_fn(combo_params)
new_variance = jax.tree_map(lambda v, g: b2 * v + (1-b2) * g ** 2, variance, grads)
v_hat = jax.tree_map(lambda v: v / (1 - b2 ** (step + 1)), new_variance)
update = jax.tree_map(lambda g, v: g / (jnp.sqrt(v) + 1e-6), grads, v_hat)
lr = lr_schedule(step, max_steps)
new_params = jax.tree_map(lambda p, u: p - lr * u, params, update)
if avg_type == 'polyak':
c = 1 / (step + 1)
new_smooth_params = jax.tree_map(lambda x, y: x * (1-c) + y * c, smooth_params, new_params)
elif avg_type == 'exponential':
new_smooth_params = jax.tree_map(lambda x, y: x * ema_rate + y * (1-ema_rate), smooth_params, new_params)
loss, _ = grad_fn(smooth_params_hat) # Eval with smoothed params
return loss, new_params, (new_variance, new_smooth_params)
init_opt_fn_polyak = lambda p : (zero_params(p), p)
init_opt_fn = lambda p : (zero_params(p), zero_params(p))
adam_sfree_polyak = functools.partial(adam_optimizer_schedulefree, lambda x, y: 0.001, avg_type='polyak')
sfree_polyak_loss = train_cifar(adam_sfree_polyak, init_opt_fn_polyak, 100_000)
adam_sfree_exponential = functools.partial(adam_optimizer_schedulefree, lambda x, y: 0.001, avg_type='exponential')
sfree_exponential_loss = train_cifar(adam_sfree_exponential, init_opt_fn, 100_000)
100%|██████████| 100000/100000 [05:03<00:00, 329.64it/s]
plot_losses([constant_loss, cosine_loss, exponential_loss, sfree_polyak_loss, sfree_exponential_loss],
['Constant LR', 'Cosine Decay', 'Exponential Avg', 'ScheduleFree (Polyak)', 'ScheduleFree (Exponential)'], 'Train Loss', ylim=1.5)
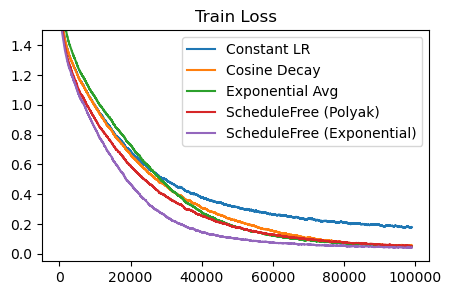
In the schedule-free optimization paper, there’s a nice graph that shows how schedule-free methods are Pareto dominant over cosine decays. In other words, for any training length, the schedule-free methods can match or beat the cosine decay performance, without knowing the training length beforehand. The implication here is we can just use schedule-free methods and train indefinitely, and not worry about losing out on performance.
Let’s see if we can recreate these results.
default_colors = plt.rcParams['axes.prop_cycle'].by_key()['color']
fig, axs = plt.subplots(1, 3, figsize=(15, 3))
for j, (compare_loss, compare_label) in enumerate(zip([sfree_polyak_loss, exponential_loss, sfree_exponential_loss],
['ScheduleFree (Polyak)', 'Exponential Avg', 'ScheduleFree (Exponential)'])):
for i, (loss, label) in enumerate(zip([constant_loss] + linear_losses + [compare_loss]
, ['Constant LR'] + [f'Linear Decay {d}' for d in [100_000, 75_000, 50_000, 25000]] + [compare_label])):
loss = np.convolve(loss, np.ones(1000), 'valid') / 1000
colors=['grey'] + [default_colors[3] for i in range(4)] + ['black']
axs[j].plot(loss, label=label, color=colors[i])
axs[j].legend()
axs[j].set_ylim(-0.05, 2)
axs[j].set_title(f'Train Loss ({compare_label})')
plt.show()
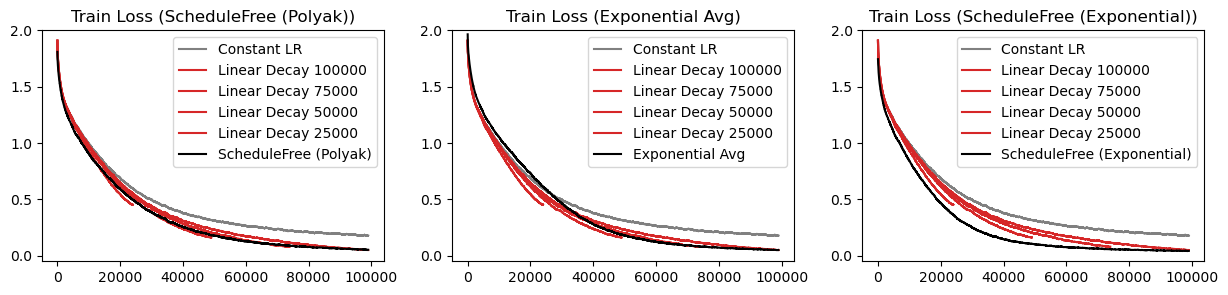
The exponential schedule-free optimizer is Pareto dominant over all linear decays!
Conclusion#
Learning rate decay is important, but the exact form of it doesn’t seem to matter much. It’s even fine to train with a constant LR for most of training, and just use a lower LR at the end once the model has stopped improving. That said, there are schedule-free methods that can achieve a similar affect to LR decay without actually doing the decay, and instead using parameter averaging to get smooth parameters. Polyak averaging has better worst-case convergence properties (theoretically), but practically it appears that exponential averaging works the best.